
Predictability is a function of complexity. The more complex the attack, the less predictable it is for instance.
Prediction
Prediction is the wrong word to use. Nevertheless, I use it myself also as the correct word – prevision – is not yet known enough. The problem with prediction is that prediction suggests that one knows the future with absolute certainty. Whereas in reality you only see a future that is a possibility and has a probability. So the word “Prevision” perfectly captures that sense. You have a vision of the future before it actually happens. That is the reason why professor De Finetti introduced the word “prevision” and why he wants us to stop using the word “prediction” and replace it with the word “prevision”.
As I give a lot of predictions, or better yet previsions, of football matches on my Twitter account, I am often confronted with people who tell me to my face that my prediction was wrong. And sometimes they are right. Fans don’t like negative predictions for their team and love the analyst to be wrong. And in those cases I am happy to be wrong. In fact, when we use these predictions to help clubs prepare for matches, then we are actually working to make sure that the prediction turns out wrong.
So let’s look at a recent prediction that was wrong:

The end result was a 3-1 win for VVV. That is a three goal difference with our prediction, in the sense that RKC had to score three more goals for the prediction to become true. So the first reason why this prediction is wrong, is that it is not a case of happenstance. It would have been very likely to be happenstance if the goal difference to make the prediction true would have been one.
If we dive into the underlying FBM model RKC has a 42% chance to win, VVV a 28% chance to win and there was a 30% chance for a draw. Nate Silver of 538 uses these probabilities to argue that he is never wrong.
If you want to make us look bad, you’ll have a lot of opportunities to do so because some — many, actually — of these forecasts will inevitably be “wrong.” – Nate Silver
If we were to follow Nate Silver’s argument then we would say that even though we gave VVV only a 28% chance, 28% chance still happen, so we were right after all! We would then continue to use all kinds of mathematics to show that a large number of predictions on average pretty much follow reality. Of course, we have done so. And for the first 144 matches, our prediction error was little more than 1% whereas the sports betting industry had a prediction error of 4%. We could then use Brier’s Score to further proof how well our predictions match up with reality. But although this is completely mathematical sound to do, it is not what I want to do.
Previsions can be wrong
The reason why I think we have to move beyond a mere mathematical check on whether a prediction was right, has to do with using previsions instead of predictions. If you also take a prevision only to be a mathematical number, then it doesn’t matter. But if you take prevision literally, i.e. as a vision of the future before the future happens, then it is not only possible to see that a prevision is wrong even though I gave the winning team a 28% chance of winning, a prevision can even be wrong even though it did give the winning team the biggest chance of winning. For the favorite might have won in a completely different fashion than that the prevision foretold. Especially in all cases where the favorite only wins with one goal difference, there is a decent chance that this was happenstance and if so it might invalidate the prevision even if the prevision was right.
If you can be wrong even when you are right, the opposite is also possible. In that case you are right even if you are wrong. Here is an example:
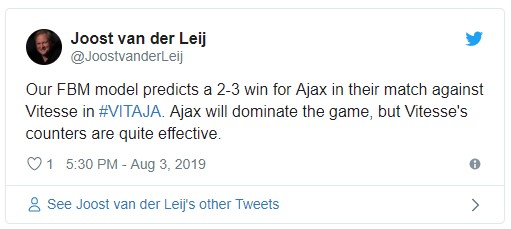
The end result was a 2-2 draw. Our FBM model gave Ajax a 53% chance to win, Vitesse a 35% chance and there was only a 12% chance of a draw. Nevertheless, it was a draw. Yet, the prevision was correct. Ajax did dominate the game and Vitesse’s counts were very effective. As it was only a one goal difference for a different outcome, this is a case of happenstance. In fact, Ajax shot a ball on the post and had quite a few other chances.
The reason why our model had this prevision is because the model bases it chances on three values: the percentage of domination, the percentage of chances and the relative attack power of each team. In this example Ajax had a domination of 84% versus Vitesse that had a domination of 8%. Ajax had 66% of the chances versus Vitesse 34%. And the Ajax had an attack power of 2.6 (rounded this gives the 3 goals for Ajax in the prevision) versus Vitesse of 1.9 (rounded this gives the 2 goals for Vitesse).
The combination of a high domination for Ajax with still a lot of attack power for Vitesse, gives the prevision of a match where one team dominates (Ajax), but where the other team counters effectively (Vitesse).
Mathematically, this prevision was quite inaccurate. As a literal prevision, it was quite accurate.
Mathematics versus a literal prevision
In my view, for a football club, a literal prevision, in the sense of describing qualitatively how the match will unfold, is more valuable than a quantitative description in terms of probability. The reason is that if a manager doesn’t like the literal prevision, he can take measures to prevent the unwanted prevision from ever happening.
When you read our match preparation of the match between PSV and Basel, you see that we lower our initial estimation of the chance of PSV winning once we get the actual lineup. The original prevision was based upon the lineup in the previous match. As soon as the actual lineups for the match are known we update our model and get an updated prevision. Originally, we foresaw a high chance of PSV winning. In our updated prevision we saw a much lower chance of PSV winning. In the end PSV won the match 3-2.
Mathematically, that means that our original prevision was much more accurate than our updated prevision. Nevertheless, for those who have watched the match, almost everyone would agree that the updated prevision – the one with a much lower chance of PSV winning – was more accurate. Until 5 minutes before the end of the match, PSV was down 1-2. PSV was very lucky to score twice in the dying moments of the match. Again, because only a one goal difference would have meant a different outcome, this is a case of happenstance. Yet, the manager would have found the less accurate updated prevision a lot more helpful than the mathematically more accurate original prevision.
Here you have an excellent example of why football clubs should never only use data. Instead they need to always use experts that can look beyond the numbers. Being mathematically correct does not mean that your numbers are actually useful. They might in fact be quite misleading. And the other way around: a prevision that actually helps the team increase the chance of winning, doesn’t have to be mathematically the best prevision.
Predictive theory

Predictive Theory (PT) is a theory by philosopher Andy Clark that states that our brain is a Bayesian brain that foresees the future. Basically, there are two parts to the brain. The first part processes sense data. The second part processes our expectation of what we expect to sense. The brain then checks to see whether our predictions of what we were about to sense fits what we actually sense. If that is the case, everything is okay. If there is a discrepancy between what we sense and what we expect to sense, then the brain tries to reason away the differences in favor of our expectations. The brain thinks that the discrepancies can be explained by us not seeing, hearing or feeling correctly. This is the neurological basis of confirmation bias. If we sense what we don’t expect to sense, our sensory data is ignored in favor of our expectation. Yet, if the discrepancy keeps consistently popping up, and the brain fails to reason it away, the brain finally gives precedence over the sense data and updates our learning about the world in light of the unpredicted sense data. Finally the brain starts to adapt our expectations in light of the unexpected things we hear, feel and see.
Associated with PT is the bottleneck problem. We can measure how much data comes in from our sense organs. It is about 1 Mbit/s per sense organ. We have quite a number of sense organs, two eyes, two ears, a nose, a mouth and our skin. So before you know it, you have about 10 Mbit/s in data coming from the senses into our brain. On the other hand we can make a good estimation of how much data we would need to stream our real live world if we were to make an exact replica of it in a virtual reality world. That would take thousands and thousands of gigabytes. Or to put it differently: what we think that is reality as it comes to us through our senses, can’t be really input from the outside world. Our sense of reality is just too rich for it to have passed for 100% through our senses. It is much more likely that most of what we experience is actually made up by our brain based on our expectation of what we are going to experience.
What our senses really do according to PT is error detection. Rather than try to capture all the data that is out there, our senses are meant to spot the things that are different from our expectation and parse that to our brain. So rather than having our brains compare a complete reality both in our expectation and our sense data, it is much more economical to only have the complete world as our expectations and our senses alerting us to what is unexpected, or an error according to our expectation. Then the brain still goes on to reason away these differences and in the case that fails, the brain is still going to update its learning so to adapt its expectations, but there is less of a bottleneck problem this way. A lot of the selective attention issues can be explained by PT this way.
What this means for football
PT has a lot of implications for football. First of all for your practice. If your practice is too predictable, your players are not going to hear what you actually have said, but rather what they expect you to say. That means that if you do start to change things, they won’t notice it. Also remember that people like what they know, but they learn from what they don’t know. So make sure you have quite a lot of surprises for your players during practice as that makes the brain rely more on what it actually senses rather than what it expects.
In my opinion, this phenomenon is in large part also responsible for the cases where a manager becomes ineffective for a group of players. He has been too predictable in the past. While he was winning with these predictable patterns, everything was okay. But as soon as the manager started losing matches and he wanted to change things around in the strategy, players literally failed to hear him because they heard what they expected him to say rather than what he actually said. Many coaches are frustrated about how players don’t do the assignments on the pitch during the match that the coach has given them. But the responsibility for this lies with the coach. If your player didn’t learn it, you didn’t teach it.
Most importantly, it shows how important good opposition analysis is. Before the match starts, your players will have an expectation of how their opponent will play. The staff has an important role to play in building up this expectation with analyses, videos and explanations of the play style of the opponent. If players enter the match with the wrong expectations, they literally don’t see what the opposing players are doing. Now and then bad errors happen on the pitch that might make the team lose, where people off the pitch ask themselves: “How in God’s name could he not see that coming?” Well the answer is: his brain did not expect that to happen, his senses let his brain know that there was an error in the expectations, but the brain reasoned the errors away and went about its business.
Of course, players with more game intelligence have this problem less. Their brains are able to expect more and have better expectations in the first place. That is the reason why game intelligence is such an important skill to develop. It helps the player overcome bad suggestions from poor opposition analysis and adapt to the new situation on the pitch.
Primary statistic
The primary statistic is the probability that a player is able to contribute to the team. See probability for an explanation.
Probability
Probability is the strength of your believes. Few people understand probability and understand what this entails. Our scientific understanding of probability has been developed by professor De Finetti. He came up with (independently but around the same time as Frank Ramsey) the idea that our probability estimations reflect how strongly or weakly we believe that something will happen.
What is the chance that Barcelona will win be the next Champion League winner? The answer is a number between 0% and 100%. There is a discussion on whether 0% and 100% are still probabilities or that 0% means that it is impossible and that 100% would be absolutely certain. I follow professor De Finetti: 0% means that is extremely unlikely, in fact so unlikely that we have no smaller number for it, but that it is still not impossible. And 100% means that it is extremely likely, in fact so likely that we don’t have a bigger number for it, but still no absolute certainty. For mathematical reasons, in almost all cases, it is best to think of probability as a number between 1% and 99%. That way you never get into the above discussion.
For most people this is a completely new and revolutionary idea to look at probabilities as it makes all probabilities subjective. That is indeed the case, because the strength of your beliefs will often differ from the strength of my beliefs. Less so if we are dealing with physics, for instance gravity. But more so when it comes to football. So for football professionals it is extremely important to get a grip on what probability means and entails.
Most people think that chance is not about the strength of your beliefs, but about the frequency with something happens. This is called Frequentism, whereas De Finetti uses Bayesian statistics. To put it bluntly: Frequentism is wrong. For many reasons, but as a philosopher the biggest problem is the Frequentist definition of chance, which is:
Chance is the frequency of something happening that has the same chance of happening.
As you can see, Frequentists use “chance” in the definition of chance. This makes this definition circular and meaningless. If you think of chance in terms of frequency, you misunderstand probability.
The correct way is to understand that chance, or probability, is about the strength of your believe. Often you use knowledge of frequencies to strengthen or weaken your belief. But there is a big gap between a frequency and the strength of a belief.
Why this is so important for football
The data revolution is happening in football. While still in its infancy, many clubs nowadays decide on player acquisition based on data analysis, among many other sources of information like scouting. There are many different ways of doing data analysis in football, but they all come down to that there are X different numbers that people look at. For instance as can be seen here:
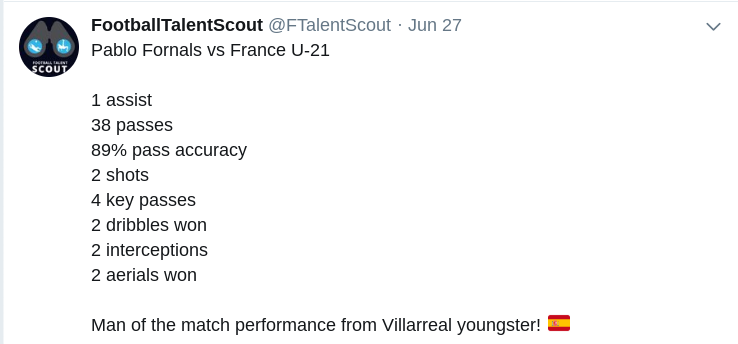
As you can see these are frequencies tied to a conclusion that it is a man of the match performance. That conclusion would be the belief. What is missing is an exact number of how strong this belief is. And what is missing is how one gets from these frequencies to the most rational strength of one’s belief. Professor De Finetti has mathematically proven that the best way to turn data into a rational belief, is Bayesian statistics.
The issue becomes even more pressing when you ask the next questions that clubs will ask, namely: is this player going to strengthen our team? This is the same question Mark Cuban ask for players of his Dallas Mavericks:

Football is more complex than basketball, so Points Per Possession (PPP) is not the right aim for football. The crucial part of the quote is: “The probability that a player is able to contribute”. That is what I mean with the question: what is the probability that a player strengthens the team.
Of course the answer to that question depends on the team. For many teams Pablo Fornals is highly likely to be a valuable player. But most of these teams can’t afford to have him play for the team. Then there is a smaller group of teams where he would not be good enough, even though they could easily afford him.
But say, for argument sake, that we run a club that could afford Pablo Fornals, then it turns out that it is very hard to come up with a probability estimation of how likely it is that Pablo would strengthen the team if you want to base yourself on traditional football data like we see here above. Especially, when you want to put it in a hard number between 1% and 99%. The situation then becomes even more problematic when you also have to consider that there are maybe five other players that the club is also considering and that we want to order these six players so we know which player has the highest chance to be a success and which player has the lowest chance.
There are so many uncertainties when it comes to this one question: is a player going to strengthen the team. The data the club uses might be wrong, incomplete or even tainted with false positives. There are many people in the club who have a strong opinion (i.e. a belief) on these players. Often, one has to work in a situation where there are still many known unknowns and there are always unknown unknowns. In situations like these it has been mathematically proven (with the Dutch Book argument) that a Bayesian network can calculate what the most rational probability assignment is.
I have developed a prototype of a Bayesian network where every scout of the club, every data analyst and every other staff member can enter how likely he thinks that a player is going to strengthen the team. Based on historical figures (for instance the frequency of success each scout, analyst or staff member has) one can give different weights to each part of the network. Once all the strengths of the beliefs of all relevant people are entered in the network, the network itself will automatically calculate the overall probability and rank all the players accordingly. It has been proven that following probabilities calculated this way, is the most rational way to make decisions.
Primary versus secondary statistics
Once you agree with me that within football it is all about the probability that a player is able to contribute to the team, then you can distinguish between the primary statistics, which is the probability that a player is able to contribute to the team, and secondary statistics, which are all other statistics that you use to come to the judgement of how probable it is that a player is going to contribute to the team.
For instance, if you want to know whether how probable it is that a certain striker is going to be able to contribute to the team, you might look at secondary statistics in the previous season like goals scored, expected goals (xG) or shots on target. These are just examples. The point is that you then use these secondary statistics to derive the primary statistic.
This derivation can either be formal or informal. With a formal derivation you actually have a statistical model where the secondary statistics are the input and where the primary statistics. This output is in the form of a value between 1% and 99%.
The same happens when a manager makes a decision only based on the secondary statistics. In that case he uses his brain to create an informal derivation of the primary statistic from the input of the secondary statistics. His brain is a Bayesian brain, a Bayesian biocomputer, able to calculate these probabilities. The reason why a club is eager to hire a great manager is in part due to the fact that the decision makers at the club, unconsciously, expect the brain of the manager to be able to calculate the primary statistic based on all the secondary input they are going to give him. Of course, the manager’s brain is much more occupied with short term gains rather than long term well being of the club. For that reason it is often much better to have a separate head of recruitment who also has a great brain that is able to compute the primary statistic, but whose brain has more of a focus on the long term.
In any case, whether you formally calculate the primary statistic or whether you have enough trust in the brains of the decision makers at the club, in the end clubs work with the primary statistic: the probability that a player is able to contribute to the team.
For more on probability, see the article about what is possible.